An LLM Made from Logic Gates
The fundamental aim of research is the discovery of new knowledge, which is contingent on undefined concepts that are difficult to benchmark. Yet current autonomous research systems are limited to the space of benchmarkable problems.
Relying on benchmarks to define the trajectory of research is counterintuitive. Aster's mission is to address this core tension: we are building autonomous research systems for open-ended problems, starting with mechanistic interpretability — the study of model internals. We chose interpretability because of its relative nascency and consequent lack of benchmarks.
Methods
We pointed our system at this task: "Create an entirely circuit-based new architecture. Make sure every single learned black-box mechanism is replaced with a learned circuit that can be directly compiled into C." Since this task is quite narrow, we borrowed the structure of the worker agent as detailed in our first report, Scaling Autonomous Research to Thousands of Agents.
Tracing circuits is an important longstanding goal in mechanistic interpretability. We wanted to ask if a model entirely comprised of logical circuits could learn language to explore progress towards this goal.
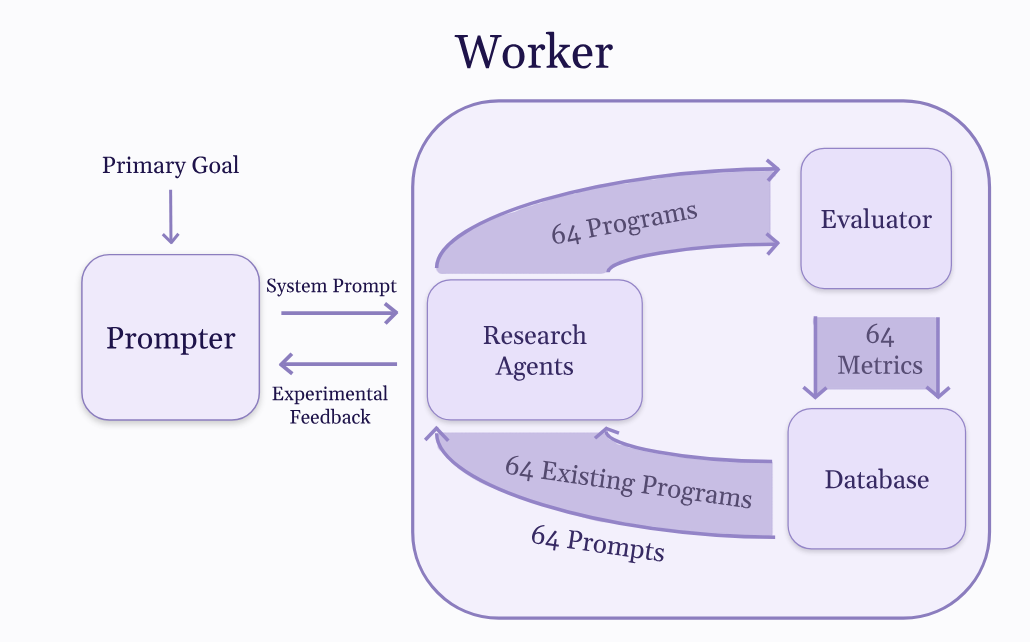
It is worth noting that the database — the set of selected "best" programs we keep for our evaluator — is biased toward only retaining programs that perform well on a benchmarkable metric; MAP-Elites, for instance, discards every cell that isn't the best in its niche. Here, we instead replace that benchmark with an LLM that:
- Judges whether a candidate solution is composed entirely of circuits and does not hack the final goal.
- If so, prefers the script with a lower cross-entropy loss after a fixed amount of time.
We also have the outer worker generate a list of restrictions the model must follow:
- Do not retain standard dense transformer-style mechanisms if they stay non-compilable and opaque.
- Do not optimize for local performance gains at the cost of full-model circuitification.
- Do not make partial edits that fail to push the whole architecture toward end-to-end compilability.
The prompter agent observes the feedback and adds to this list whenever it sees an undesirable solution slip through.
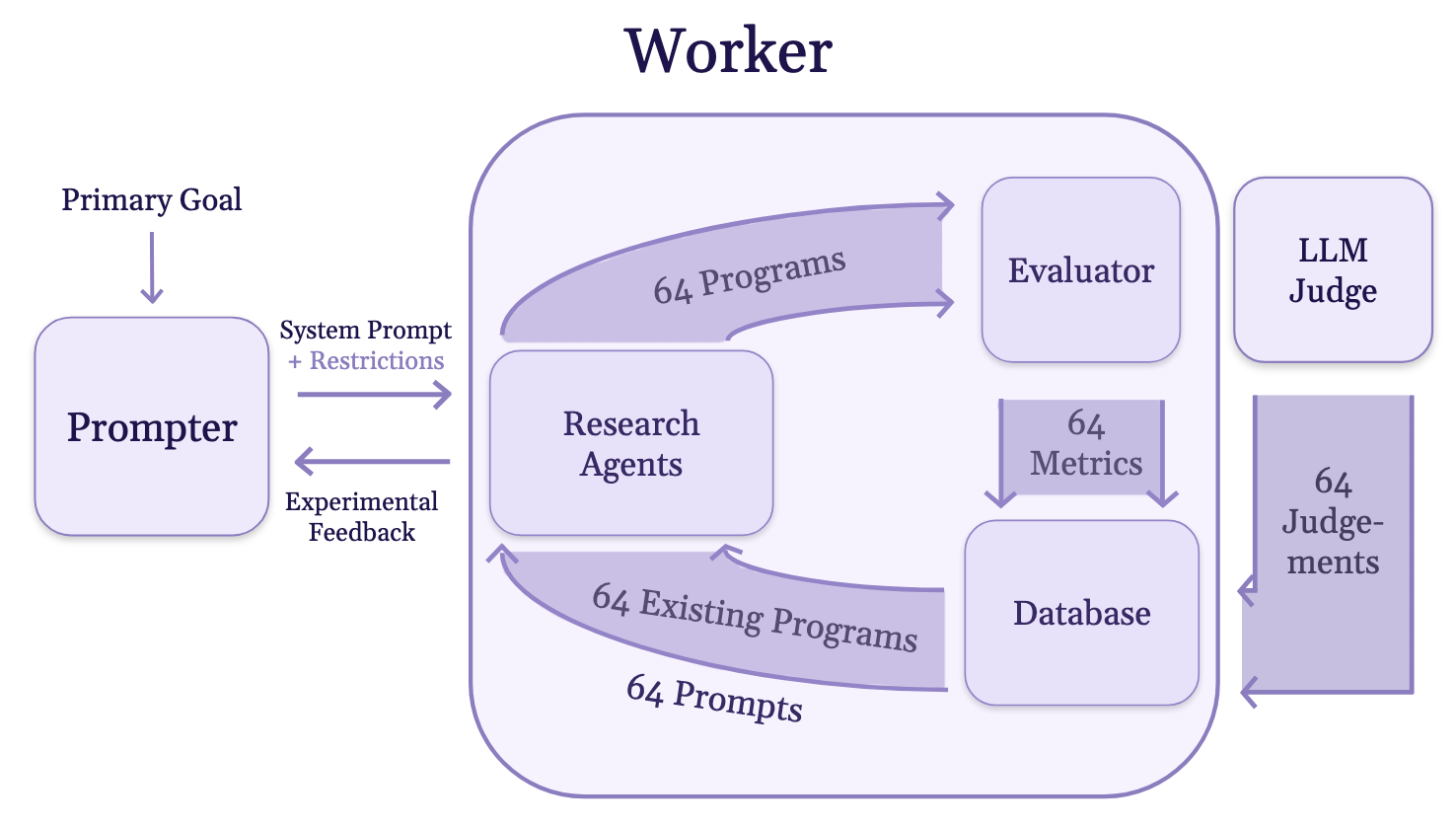
After a few iterations of the inner program, the outer agent analyzes and summarizes all findings. If a run breaks the restrictions, the outer agent updates the list and launches again. Once it declares a run to have found a sufficiently interesting solution, it concludes and surfaces the most interesting and scientifically valid solutions to the user.
Results
The system surfaced two scientifically interesting programs: one that turned the entire model into a ternary circuit, and one that turned only the feedforward layer into a circuit.
Toy task
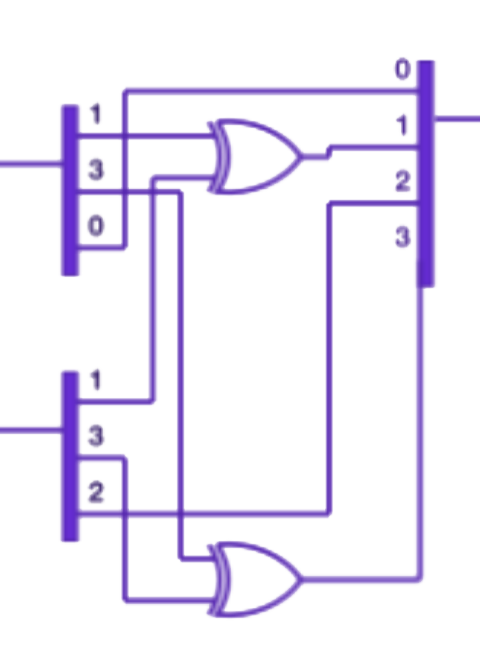
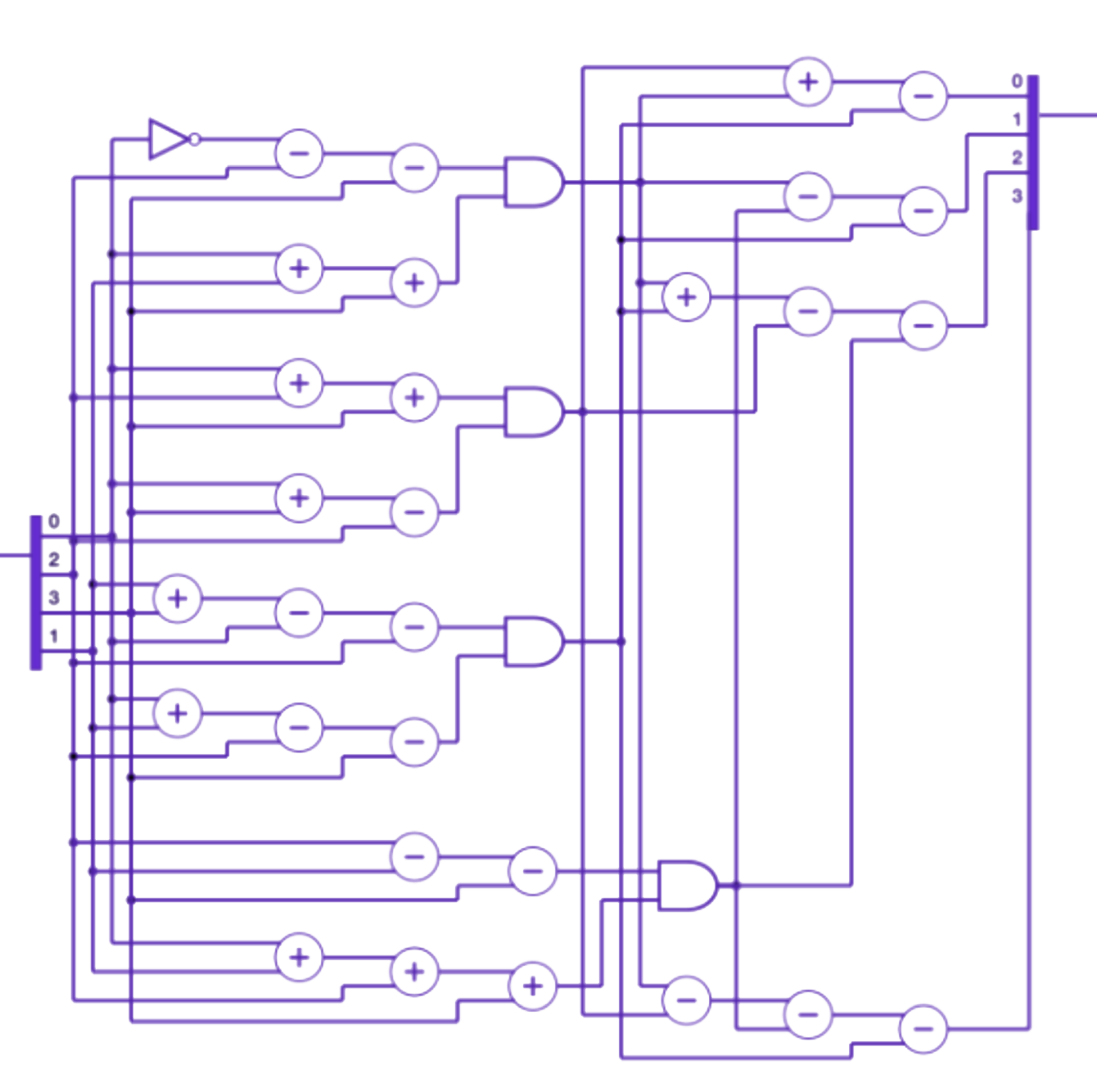
The circuitified model is composed entirely of logical operations in C, without ever performing a matrix multiplication. This model:
- Only learns weights for the embedding layer, and uses tied embeddings.
- Learns fixed tokens to attend to per head.
- Builds a large circuit over previous tokens to predict the next token.
- Allows continuous signals to flow up to the unembedding layer, where they are added or subtracted before passing through logic gates.
We applied the full circuit language model to a toy task to observe a simple
circuit: predicting the next token in a binary sequence such as 010101010. We
scaled the model down to the smallest version the code allows and trained it on
this problem.
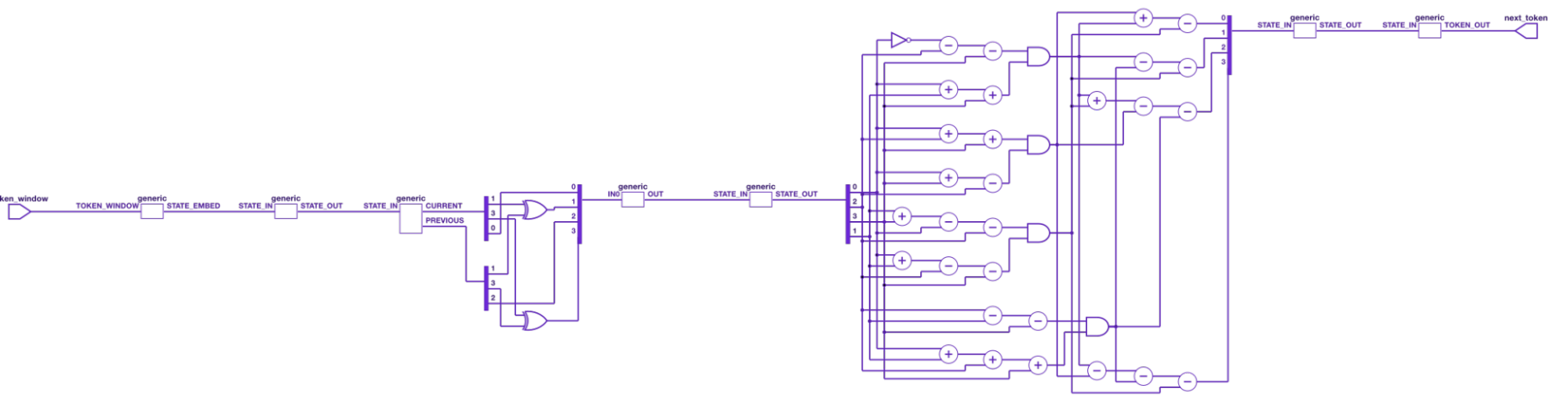
The only learned weights in the model — the embeddings — are:
token 0 → [-0.0048, -0.1606, -0.2975, -0.2457]
token 1 → [+0.2796, +0.3321, +0.0694, +0.7137]Attention has two input features, meaning the circuit learned to attend only to the current token and the previous token — exactly what this problem requires.
Scaling
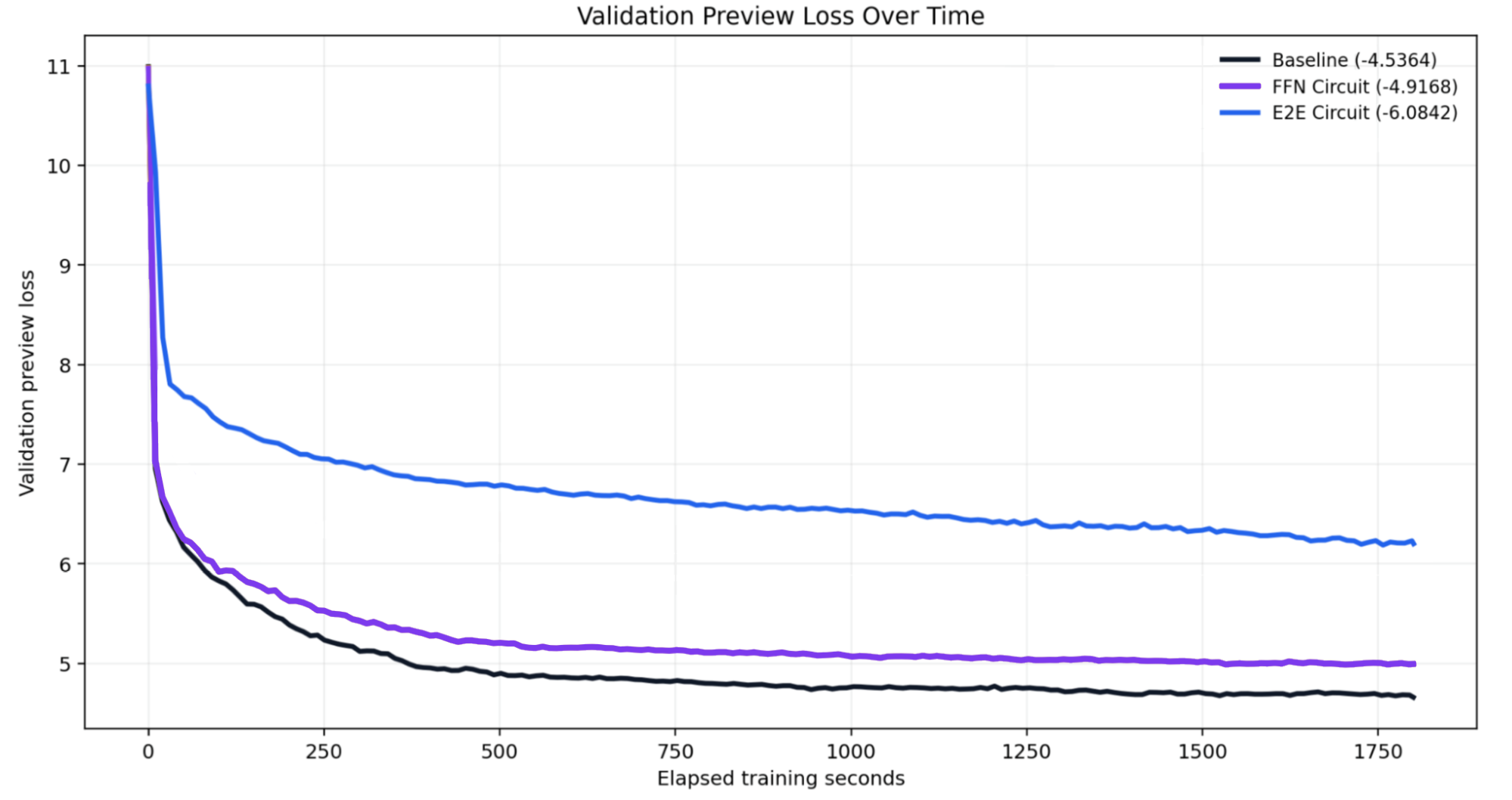
The full circuit language model was discovered while training for 30 minutes on 10M parameters. To see whether the architecture improves with scale, we ran a one-hour training run on a 100M-parameter model. Below are the results for 10M versus 100M parameters.
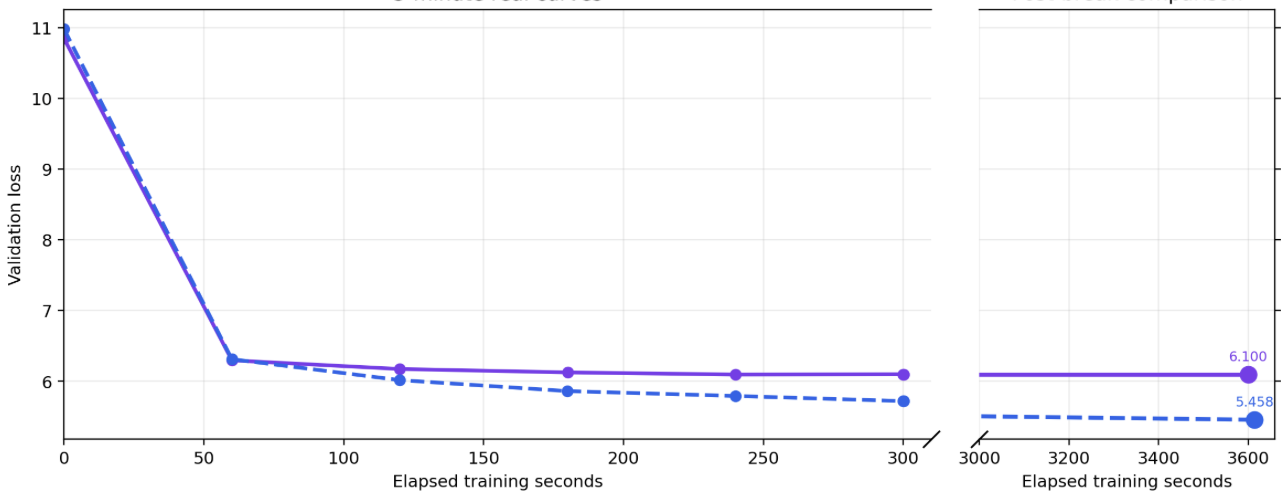
The architecture discovered by the model improves in quality with scale.
Inference
Finally, we tested inference on the 100M-parameter model. Prompted with "i think", the model returned:
i think that she has been a good time to do it.
I'm not sure that I can't do it.
I'm not sure what I'm
Despite being composed entirely of circuits, the model clearly has a rudimentary understanding of grammar and syntax and is capable of learning basic language skills.
So what?
This is a single example that illuminates the road ahead for pointing autonomous research systems at open-ended problems. From here on, the limit may well be our own imagination. We look forward to seeing where this research takes us and what innovations it might drive.
Contributors
- Emmett Bicker
- Olivia Long